| 1.3. Une composante multidimensionnelle | ||
|---|---|---|
 | Chapitre 1. L'approche SOLAP |  |
| 1.3. Une composante multidimensionnelle | ||
|---|---|---|
| | Chapitre 1. L'approche SOLAP | |
Après la composante cartographique de l'approche SOLAP, cette section présente sa composante multidimensionnelle, reposant sur le système OLAP. Une brève mais nécessaire introduction au domaine de l'informatique décisionnelle précède cette présentation du "processus d'analyse interactif pour l'aide à la décision" OLAP.
L'informatique décisionnelle, Business Intelligence ou Decision Support System en anglais, peut se définir comme l'ensemble des technologies permettant de traiter, valoriser et présenter les données à des fins de compréhension, d'analyse et de décision [5].
L'informatique décisionnelle s'appuie sur un système d'information décisionnel qui s'oppose ou système d'information transactionnel. Dans une entreprise, chaque service dispose en général de données "métier" dans une ou des bases de données relationnelles. Entre chaque service (logistique, marketing, finance, etc.), les données sont rarement structurées de la même façon. La prise de décision peut également nécessiter des données externes à l'entreprise, par exemple des données diffusées sur Internet. Pour obtenir une vue d'ensemble et permettre aux analystes et responsables de l'entreprise des prises de décision plus pertinentes, les données vont devoir être filtrées, croisées, transformées et reclassées dans un entrepôt de données (datawarehouse) ou un entrepôt de marché (datamart) : celui-ci est généralement généré à partir des données globales de l'entrepôt, il en représente un sous-ensemble, regroupant par exemple les données d'un métier particulier.
A noter que l'informatique décisionnelle ne vise pas à remplacer les systèmes transactionnels, elle vient plutôt les compléter pour répondre plus efficacement aux besoins d'analyses.
Comme illustré sur la Figure 1.3, un système d'informatique décisionnelle est généralement composé des quatre briques de fonctions suivantes [6] :
La collecte des données : ce service fait généralement appel à un logiciel ETL (Extract Transform Load) pour préparer les données qui seront stockées dans des bases spécialisées par métier et organisées en vue de leur analyse. Le processus ETL se décompose en trois phases :
l'extraction des données : aller chercher les données depuis des sources hétérogènes : SGBD, applications, fichiers, pages Web Internet ;
la préparation/transformation : vérifier qu'une donnée est cohérente par rapport aux données déjà existantes dans la base cible, la convertir si besoin est ;
le chargement : prendre en compte la gestion du format final des données.
Le stockage des données : les données brutes du SGBDR de production ne se prêtent pas facilement à des analyses, les données sont donc stockées dans les bases spécialisées datawarehouse et datamart. Bill Inmon est un des créateurs du concept, il définit l'entrepôt de données comme « une collection de données thématiques, intégrées, non volatiles et historisées pour la prise de décisions » [6].
La diffusion ou distribution des données : le portail informationnel décisionnel de l'entreprise (EIP : Enterprise Information Portal) ouvre un accès sur l'entrepôt de données. Le portail (Web Services) permet de faciliter l'échange et le partage d'information entre les utilisateurs.
L'exploitation ou présentation des données : les données sont alors accessibles et exploitables par différentes familles d'outils : des tableaux de bords, des outils de datamining, des outils OLAP.
Figure 1.3. Les quatre fonctions d'un système décisionnel

Les quatre fonctions : 1) collecte ; 2) stockage ; 3) diffusion ; 4) exploitation. Source : [6].
Les grands principes de l'informatique décisionnelle étant posés, la section suivante s'intéresse plus particulièrement aux principes de l'OLAP pour l'exploration des données stockées dans l'entrepôt.
Edgar Frank Codd introduit en 1993 le terme OLAP qui « désigne une catégorie d'applications et de technologies permettant de collecter, stocker, traiter et restituer des données multidimensionnelles à des fins d'analyse » [8]. Une définition plus générique suggérée par Nigel Pendse en 1998 se résume dans l'acronyme FASMI (Fast Analysis of Shared Multidimensional Information) : "analyse rapide d'information multidimensionnelle partagée" [9]. Codd complète sa définition du concept OLAP par douze règles de conception [6]. Cette liste originale a été complétée depuis par de nombreuses règles complémentaires mais elle constitue toujours une référence :
multidimensionnalité : la nature conceptuelle du modèle OLAP ;
transparence : l'utilisateur ne se soucie pas de l'emplacement physique du serveur ;
accessibilité : la mise à disposition de toutes les données pour l'utilisateur ;
stabilité : la performance ne dépend pas du nombre de dimensions, les temps de réponses sont constants ;
client-serveur : l'architecture du système OLAP ;
dimensionnement : la généricité du dimensionnement, les dimensions sont indépendantes ;
gestion complète : le serveur assure la gestion des données éparses clairsemées, c'est à dire les valeurs manquantes dans la matrice ;
multi-utilisateurs : le serveur assure la gestion de mises à jour, d'intégrité et de sécurité pour un support multi-utilisateurs ;
inter-dimensions : le serveur permet des opérations entre et dans les dimensions ;
intuitivité : la facilité de manipulation des données ;
flexibilité : la souplesse pour l'édition et l'affichage des rapports ;
analyse sans limites : le nombre de dimensions et de niveaux d'agrégation permet des analyses complexes.
Un système OLAP s'intègre typiquement dans une architecture à trois niveaux : une base de données multidimensionnelle, un serveur OLAP, un client OLAP. Le serveur fournit une vue multidimensionnelle des données, il gère les données agrégées et détaillées et l'ensemble des métadonnées. Le client OLAP offre une interface utilisateur simple, sans connaissance d'un langage de requête pour explorer les données, il affiche les données sous formes de graphiques ou de tableaux.
![[Note]](../images/note.gif) | |
Le serveur OLAP interroge une base multidimensionnelle en utilisant généralement le langage MDX (MultiDimensional eXpression). Créé par Microsoft, le langage MDX s'encapsule aujourd'hui dans des balises XMLA (XML for Analysis). XMLA définit l'accès à des systèmes analytiques comme OLAP ou les outils de datamining. Contrairement à SQL, MDX n'est cependant pas maintenu par une organisation indépendante de normalisation et d'après Julian Hyde, fondateur du serveur Mondrian, l'interopérabilité entre clients et serveurs OLAP « n'est pas pour aujourd'hui » [7]. |
Le concept OLAP s'accompagne d'un vocabulaire spécifique à l'approche multidimensionnelle. Celle-ci introduit tout d'abord la notion de dimension, ou axe : il s'agit d'un thème de l'analyse. La dimension modélise un des attributs sémantiques associés aux faits observés : par exemple sa date (dimension temporelle), son lieu (dimension spatiale), sa catégorie (dimension thématique). Une dimension regroupe donc des données du même type. L'hypercube est la construction multidimensionnelle formée de la conjonction de plusieurs dimensions indépendantes. Une mesure ou "population d'analyse", souvent de type numérique (prix, quantité), correspond à l'hypercube structuré par plusieurs dimensions choisies : pour une mesure à trois dimensions, on peut donc représenter l'hypercube par un cube (Figure 1.4). Une position représente la valeur d'une dimension. Le croisement des positions sur chacun des axes d'étude sélectionne une unique cellule, ou fait.
L'agrégation des données est une notion fondamentale de l'OLAP : afin d'optimiser les temps de calcul, les membres d'une même dimension peuvent être organisés en une hiérarchie de relations 1-n, arborescence comparable aux arbres logiques. Les opérations d'agrégation les plus fréquentes sont la somme et la moyenne, elles permettent de calculer rapidement les valeurs associées aux positions parents. Par exemple, on peut décomposer le temps suivant une hiérarchie à trois niveaux : les années au niveau 1, les trimestres au niveau 2, les mois au niveau 3 (voir Figure 1.4). A noter qu'une dimension peut se décomposer suivant plusieurs hiérarchies : l'année pourrait se décomposer en mois puis en jours. L'agrégation des données multidimensionnelles permet de mémoriser le résultat des calculs dans la base et d'augmenter ainsi les performances lors de l'interrogation. En contrepartie, l'agrégation nécessite un espace de stockage conséquent. Par opposition, la notion de formule correspond à un calcul effectué à la volée, le résultat n'est pas stocké en base.
Figure 1.4. Exemple : un cube OLAP et le principe d'agrégation
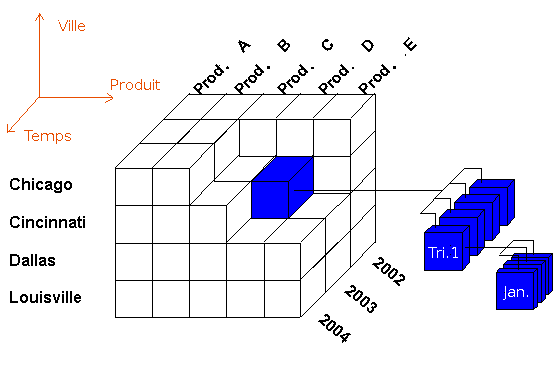
La mesure "nombre de produits vendus" repose ici sur trois dimensions : produit, temps, ville. Le fait dans la cellule bleue indique le nombre de produits D vendus en 2003 à Cincinnati. La dimension "temps" est associée à une hiérarchie sur trois niveaux pour agréger les mois en trimestres et agréger ces trimestres en année. Source : à partir de Oracle (consulté le 30 avril 2009).
L'hypercube permet donc d'organiser le stockage agrégé des données selon une granularité (un niveau de détails) plus ou moins importante. Le concept OLAP propose des mécanismes dits "opérateurs", pour naviguer dans les hiérarchies. Grâce à leur facilité d'utilisation et leur rapidité, l'utilisateur se concentre sur son analyse et non sur les moyens utilisés à cette fin. Les principaux opérateurs permettent de :
pivoter (pivot ou swap en anglais) : cet opérateur permet d'interchanger les dimensions ;
forer (drill-down) : cet opérateur permet de descendre dans la hiérarchie d'une dimension (exemple : passer de l'année au mois) ;
remonter (drill-up) : cet opérateur permet au contraire de remonter dans la hiérarchie d'une dimension (exemple : du mois à l'année) ;
forer latéralement (drill-across) : cet opérateur permet de passer d'un membre de dimension à un autre (exemple : telle ville au lieu de telle autre), ou de passer d'une mesure à l'autre (exemple : le nombre de produits ramenés en magasin plutôt que le nombre de produits vendus).
L'architecture d'un système OLAP distingue des approches différentes suivant la technologie employée à son implantation : les approches sans serveur OLAP (bases de données relationnelles), ROLAP (Relational OLAP), MOLAP (Multidimensional OLAP) et HOLAP (Hybrid OLAP, combinaison optimisée des deux premières). Dans le cas de l'approche ROLAP, toutes les données, qu'elles soient détaillées ou agrégées, sont stockées dans une base de données relationnelle. Celle-ci doit alors être structurée selon des modèles particuliers : un modèle en flocon, un modèle en étoile, un modèle dit mixte ou un modèle en constellation (voir l'annexe "Structure des bases ROLAP"). Le serveur extrait alors les données par des requêtes SQL avant de les interpréter en vue multidimensionnelle pour les présenter au module client. Même si les performances de l'architecture MOLAP sont supérieures aux trois autres, ces dernières offrent des performances qui dépassent grandement celles des systèmes transactionnels pour des requêtes de nature décisionnelle [4]. Le Tableau 1.1 compare ces différentes approches.
| Caractéristiques | Architecture sans serveur OLAP | Architecture Relationnelle-OLAP | Architecture Multidimensionnelle-OLAP |
|---|---|---|---|
| Coût | Coût moindre, car aucun serveur OLAP requis | Nécessite l'achat d'un serveur ROLAP | Nécessite l'achat d'un système de gestion de base de données multidimensionnel et un serveur MOLAP |
| Structure de données | Simule une structure multidimensionnelle | Simule une structure multidimensionnelle | Supporte une structure multidimensionnelle physique |
| Préparation des données agrégées | Nécessite plusieurs manipulations et des connaissances particulières | Le serveur se charge de produire les données agrégées | Le serveur se charge de produire les données agrégées |
| Stockage des agrégations | Nécessite le pré-calcule complet des données | Optimisation des données calculées à la volée des données pré-calculées | Optimisation des données calculées à la volée des données pré-calculées |
| Optimisation | Aucune. Requiert beaucoup d'espace disque et de temps de pré-calcul | Optimise le temps de pré-calcul, mais peut nécessiter plus d'espace que le MOLAP | Optimise l'espace disque et le temps de pré-calcul |
Selon C. Franklin (1992), « environ 80% des données contenues dans les entrepôts de données disposent d'une composante spatiale » [10]. Si les outils OLAP proposent traditionnellement des tableaux et diagrammes pour explorer les données multidimensionnelles d'un entrepôt, de nombreux constructeurs réalisent la valeur ajoutée de proposer en plus une visualisation cartographique. Si par exemple l'utilisateur cherche à considérer un facteur de proximité (ventes en fonction du code postal des clients), la représentation de ces données sur une carte lui fournit une réponse immédiate. La tâche serait ardue dans un tableau. La carte fournit à l'utilisateur une représentation logique et intuitive des données, elle favorise sa compréhension des phénomènes et facilite son processus de pensée et ses découvertes de connaissances. L'utilité de l'intégration de la cartographie au sein des outils d'analyse OLAP est reconnue par un nombre grandissant d'entreprises [11]. La mise en oeuvre efficace et optimisée d'un tel bénéfice est l'objectif de l'approche SOLAP.
| |  | |
| 1.2. Les systèmes d'information géographique |  | 1.4. La combinaison SOLAP |